基本组成部分
使用一个 Prolog 的实现,读取/编译一个由 facts 和 rules 组成的 knowledge bases 后,向它发送 query 启动一次 称为 proof search 的 查询过程。 在这一查询过程中,Prolog 的实现将通过一种匹配(Unification)机制,尽力将 query “匹配”(术语称 match 或 unify)到某个 fact 上 (这个 fact 可能是由 rules 推导得出的,而不是直接由程序员写在 knowledge base 里的)。匹配过程在 整个查询过程中一般会 发生多次。Prolog 编程指的就是编写 knowledge bases。
Knowledge base 完全由 clauses 组成, clauses 必由.结尾。每一条 clause 要么是 fact,要么是 rule。
- rule:每一条 rule 使用
:-隔开“后件”与“前件”,其左边的部分称为head of rule,右边部分称为body. 换句话说,:-应当读作"if",而head :- body读作“if the body of the rule is true, then the head of the rule is true”。其中,body 部分至少由一个 goal 组成,多个 goals 之间可用,隔开。,读作"and"。若想用不同的后件推导出同一个前件,即使用"or"连接多个前件,则应当在 body 处使用;连接多个前件。但可读性更高的方法是另起个新的 rule(仍然使用同样的后件,但前件不同) - fact:每一条 fact 不过是一条 degenerate rule,即一个无前件的 rule
基本语法
任何一个 fact、rule 和 query 均由一个 term 直接构成,且这个 term 要能组成一个 predicate(或称 procedure)。
有四种 term:
- atom:形式上以小写字母开头(如
a、cyl、a_b),或是被单引号包裹(如'd b'),或是由一些特殊字符组成(如+、:-等。这种 atom 通常具有语义) - number:形如
23,1001,0,-365 - varaible:形式上由大写字母开头,唯一例外是
_(匿名变量)。此类 term 有一种被 instantiate 的潜力——即被另一个 term 替代的潜力(作用见下文)。形式上相同的多个 varaible ,在每一个匹配过程中必被 instantiate 到同一个 term 上(匿名变量_是例外,多个_可以不被 instantiate 到同一个 term 上) - complex term:在形式上,由一个被称为 functor 的 atom 打头,后跟一个参数序列(由
()包围,各参数使用,分割。其长度被称为 arity)。参数序列中的一个参数可以是任何一种 term。如果把 functor 定义为一个 operator,则该 functor 和作为其参数的 atom 可以以一种自定义的方式(前缀、中缀、后缀)排列(见9.4节,本文略)
要组成一个 predicate,必须使用一个 atom 或一个 complex term。
匹配(Unification):一种形式上的满足
“匹配”的定义
据前述,查询过程实质上是多次尝试让一个 query 匹配到某个 fact 的一个过程。一个 query 和一个 fact 均由一个 term 直接构成,因此 query 和 fact 的“匹配”问题归根结底是两个 term 的匹配问题。定义两个 term 匹配规则如下:
- If term1 and term2 are constants(atom 或 number 都是一种 constant), then term1 and term2 match if and only if they are the same atom, or the same number.(值得一提的是
'aa'和aa会被视为匹配的) - If term1 is a variable and term2 is any type of term, then term1 and term2 match, and term1 is instantiated to term2. Similarly, if term2 is a variable and term1 is any type of term, then term1 and term2 match, and term2 is instantiated to term1. (So if they are both variables, they’re both instantiated to a same new varibale, and we say that they share values.)
- If term1 and term2 are complex terms, then they match if and only if:
- They have the same functor and arity.
- All their corresponding arguments match
- and the variable instantiations are compatible. (I.e. it is not possible to instantiate variable X to mia, when matching one pair of arguments, and to then instantiate X to vincent, when matching another pair of arguments.)
- Two terms match if and only if it follows from the previous three clauses that they match.
proof search——构建搜索树
knowledge base
f(a).
f(b).
g(a).
g(b).
h(b).
k(X) :- f(X),g(X),h(X).对查询k(X). 有如下搜索树:
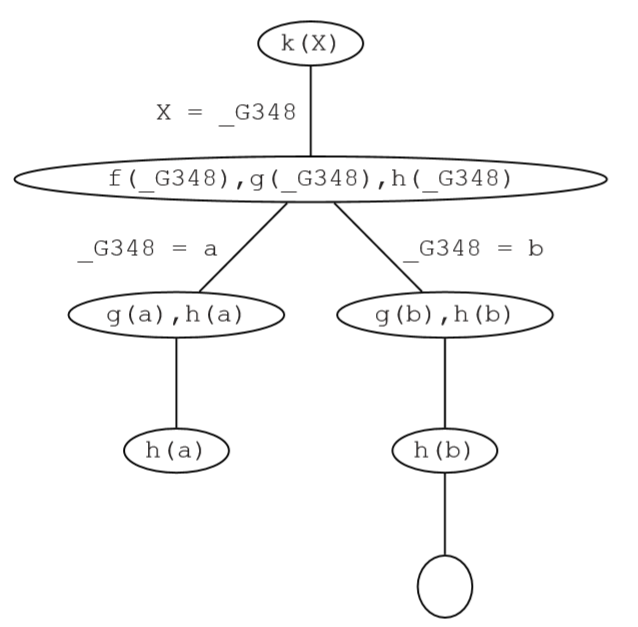
whenever it has a list of goals, Prolog tries to satisfy them one by one, working through the list in a left to right direction
Points in the search where there are several alternatives for matching a goal against the knowledge base are called choice points. Prolog keeps track of choice points and the choices that it has made there, so that if it makes a wrong choice, it can go back to the choice point and try something else. This is called backtracking
The nodes of the tree say which are the goals that have to be satisfied at a certain point during the search and at the edges we keep track of the variable instantiations that are made when the current goal (i.e. the first one in the list of goals) is match to a fact or the head of a rule in the knowledge base. Such trees are called search trees and they are a nice way of visualizing the steps that are taken in searching for a proof of some query. Leave nodes which still contain unsatisfied goals are point where Prolog failed, because it made a wrong decision somewhere along the path. Leave nodes with an empty goal list, correspond to a possible solution. The information on the edges along the path from the root node to that leave tell you what are the variable instantiations with which the query is satisfied
匹配算法(unification algorithms)
在深度优先搜索 search tree 的过程中,Prolog 使用一种 optimistic unification algorithm 来为一个节点匹配。即不进行 occurs check(一种花费额外开销 peek inside the structure of the terms they are asked to unify,来在实施匹配之前判断能否匹配的机制) 。这可能导致匹配过程无法终止。
附录:unification vs. pattern match
| pattern matching | unification |
|---|---|
| Matches a syntactic pattern to a data object. | Matches a data object to a data object. |
| mutable variables or single-assignment variables | logical variables |
| one-sided: Only assigns to variables on the left. | two-sided: Assigns in both directions. |
| No constraints are created. | Can create equality constraints. |
| lexically restricted: Only assigns to variables that occur syntactically in the statement. | lexically unrestricted: Assigns to variables that do not occur syntactically in the statement. |
| sequential–Assignments must occur in the presented order. | non-sequential–Assignments can be done in any order. |
| non-idempotent–Assignments cannot generally be repeated. | idempotent–Assignments can be repeated without changing the effect. |
| A single pattern can match different terms with different structures. | A term can only match another term with the same structure. |
来源:http://www.unobtainabol.com/2016/04/unification-things-pattern-matching.html
形式之外:语义
Prolog 预定义了一些具有“意义”的、 用于充当 functor 的 term。“有意义”的 term 指的是, Prolog 的实现并不(只)拿该 term 用于对某个 fact 的形式上的匹配,而是另有他用(也就是具有一定语义)。这一“他用”发生在一个 sandbox 中,程序员需要了解该处理将导致的效果(也就是其语义)来加以利用。
使用这些 term 充当 functor 的 complex term 不能充当 fact。因为 fact 不应该有语义。运行时只有 queries 和 rules 能携带并发挥语义。
=与==
=/2在语义上,判断两个参数是否匹配。这一判断过程若涉及变量,则会对变量进行 instantiate 操作。反义词\=/2;==/2类似,但若涉及变量,并不进行 instantiate 操作。反义词\==/2
.与列表
Prolog 预定义了[]和./2这两个 term,它们合称 list constructors。./2的语义是“有序地排列两个参数组成一个 non-empty list,其中第二个参数必须是一个[]或一个 non-empty list”。
Prolog 提供了一种语法糖,使得程序员可以避免使用./2来构建 non-empty list。例如.(.(a,[]),.(.(b,.(c,[])),[]))可简写为[[a],[b,c]]。
对任意 non-empty list,可以在试图用一 non-empty list 匹配它时,使用|分割后者,使得后者能在一次匹配尝试中分别独立地匹配前者的两个部分(head 与 tail)。
non-empty list 是一种递归定义的结构(实际上是一棵二叉树),因此通常也使用具有递归形式的 rule 来处理它(该 rule 以 reduce 的方式进行处理是很常见且高效的)。利用|,可以通过具有递归形式的 rule 来递归匹配一个 non-empty lisy。
is与算术
is/2在语义上判断两个参数是否匹配。 这一判断过程要求第二个参数是由 +/2,*/2,-/2, mod/2充当 functor 的 complex term,该 complex term 将被转换为一个 number 用于匹配。
类似地,>/2、>=/2、</2、<=/2、=:=/2、=\=/2在语义上判断第一个参数是否大/大等/小/小等/等/不等于第二个参数。两个参数均会被转换为一个 number 以进行匹配。
Examining Terms
Types of Terms
Prolog provides a couple of built-in predicates that test whether a given term is of a certain type.
- atom/1 Tests whether the argument is an atom.
- integer/1 Tests whether the argument is an integer, such as 4, 10, or-6.
- float/1 Tests whether the argument is a floating point number, such as 1.3 or 5.0.
- number/1 Tests whether the argument is a number, i.e. an integer or a float
- atomic/1 Tests whether the argument is a constant.
- var/1 Tests whether the argument is uninstantiated.
- nonvar/1 Tests whether the argument is instantiated.
The Structure of Terms
- functor/3 will tell us what the functor and the arity of this term are
- arg/3 tells us about arguments of complex terms. It takes a number N and a complex term T and returns the Nth argument of T in its third argument. It can be used to access the value of an argument
- ’=…’/2 takes a complex term and returns a list that contains the functor as first element and then all the arguments
干涉 proof search 过程
程序员可以使用以下 term 来干涉 proof search 过程。
- !/0:读作 cut。将其置于任何一个 goal 之后。这将阻止它左边的 goal 被 backtrace。这可能会影响程序的语义
- fail/0:用于充当一个 goal,且对该 goal 的匹配将立刻失败。这将导致一个 backtrace。cut 常常与 fail 连用(作为两个连续的goal)组成一个 cut-fail combination,用于“辅助推导出某个后件”的例外前件(if…except for…then 中的 except for 部分)
- +/1:Negation as failure. 相当于 cut-fail combination
在查询时操作 knowledge base
见第11章。本文略